Chemnitzer Linuxtage 2025 - Notizen
/ home / computer / .
Table of Contents
Details
- Einführung in nftables
- Kubernetes ist genial, aber ggf. brauche ich es gar nicht?
- Incus vs. Docker
- PostgreSQL Enterprise Features
- So funktioniert der Linux I/O-Stack
- Warum sollte man BTRFS verwenden?
- Tausend Freiwillige, ein Ziel
- Openwashing ans Licht!
- Karten. Daten. Open Source. Unsere Reise zu GISA Maps
- Intenet Archive Scholar: Preserving the scholarly record
- Open Street Map ist (k)eine Karte
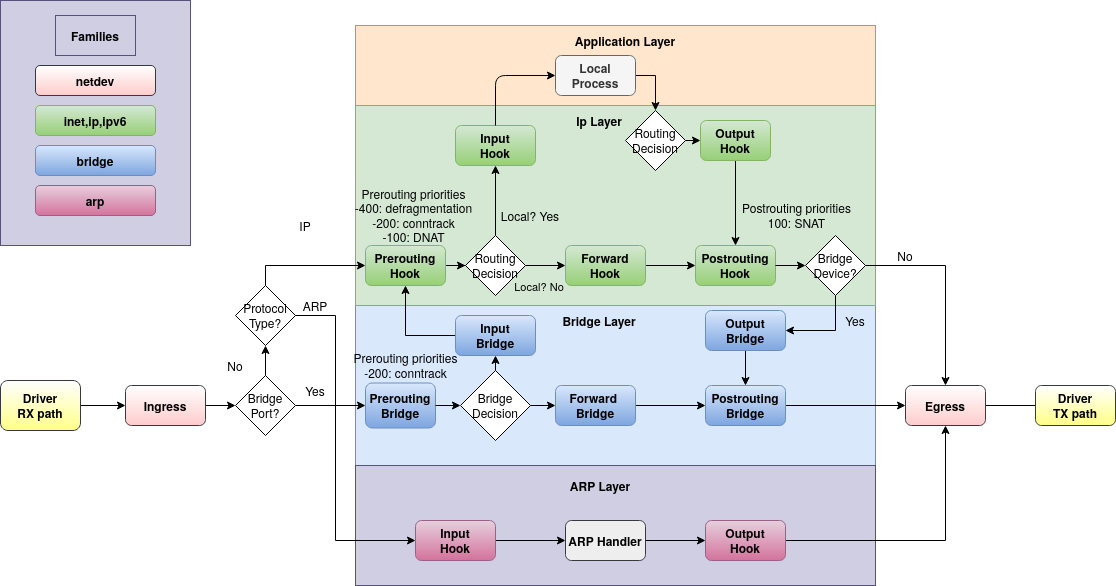
Einführung in nftables
Vortrag von Jens Meissner
- Nachfolger von
iptables, ip6tables, arptables, ebtables.
- Neuer Paketfilter von Linux.
- Macht NAT, flow-controll, logging.
- CLI:
nft, Kernelmodul: nf-tables.
- Atomare änderungen.
- Bessere Performance (Bytecode-Interpreter).
- Ist
iptables rückwärtskompatibel.
- Grafik: https://people.netfilter.org/pablo/nf-hooks.png

table ---- family - inet, ip, ip6
^ -- type - ...
chains <
^ -- hook - input, output, forward
rules ---- statement - accept, drop, reject
- inet = ipv4 + ipv6
- Braucht Kernel >= v3.13
$ nft add table <family> <name>
$ nft add table inet filter
$ nft list tables
$ nft add chain inet filter input {type filter hook input priority 0 \;}
$ nft list chains
$ nft list table ...
$ nft add rule <family> <table> <chain>
$ nft list chain
$ nft list ruleset
$ nft -a list ruleset
$ nft delete rule inet input handle 3
$ nft list ruleset > nftables.conf
$ nft -f nftables.conf
nft> flush ruleset
#!/usr/sbin/nft -f
$ chmod +x nftables.conf
/etc/nftables.conf
$ systemctl enable nftables
$ nft list set ip prefilter blocklist
Kubernetes ist genial, aber ggf. brauche ich es gar nicht?
Vortrag von Thomas Güttler, Syself
Ziele
- Hardware effizient nutzen
- Kein Vendor-Lock-In
- Klare Schnittstelle
- Validierung
- Autoscaling
- Deklarativ
- Resilienz
- Website: https://kubernetes.io/
$ kubectl apply -f deployment.yaml
- KRM: Typen –> Instanzen
- Deployememt
- Metadata
- Specifikationen
- Status
- Resources
- Namespaces
- Probes: liveness, readyness, startup
- CRD - Custom Resource Definition
- Validieren: YAML –> {
kubectl | Helm} –> API-Server
- RBACs
- Cloudnative:
ssh ist tabu!
- Bei Stateful Anwendungen etwas schwierieger, DB nutzt Storage
- cnPG - Cloud Native PostgreSQL
- Stateful Object Storage MinIO
- Grenzen:
- 110 Pods/Node
- 5k Nodes
etcd 8 Gbyte*.yaml 3 Mbyte
- Kubernetes Cluster in EINEM RZ, nicht strecken! Ist aber keine Vorgabe von Kubernetes…
Incus vs. Docker
Von Fabian Torns
incus - system container
docker - application container
PostgreSQL Enterprise Features
Vortrag von Michael Banch, Credativ
- Folien organisieren!
- QUEL –> SQL
- 7-köpfiges Core Team, 30 Committer PostgreSQL Development Group (PGDG).
- Viele (auch proprietäre Forks) min. 14!
- Einziege Community owned OSS Database.
- Forks sind teilweise in Extensions übergegangen (3).
- PostgreSQL Wire Protocol (Clients).
- Database of Databases: https://dbdb.io/browse?compatible=postgresql
- Bei “Autonomen Transaktionen” (autonomous transactions) ist PostgreSQL schecht.
- Enterprise Anti-Feature: BSD/MIT artige Lizenz.
- Major Release ca. einmal pro Jahr: ~ Sep/Okt
- Code freeze ~ April
- 5 Jahre Support
- 1/4 jährlicher Point-Release, Feb, Mai, Aug, Nov - nur Bugfixes
- Install from: {yum | zypp | apt}.postgresql.org
- WAL + “Commit Log”
pg_checksums, Version von Credativ: https://github.com/credativ/pg_checksumsamcheck, https://www.postgresql.org/docs/current/amcheck.html- Seit PostgreSQL 16 gibt es eine STIG: https://www.crunchydata.com/blog/crunchy-data-postgresql-16-security-technical-implementation-guide-released-by-disa
- PostgreSQL Audit
- Interoperatbilität
- Foreign Data Wrapper (FDW)
- CDC-Kafka
- Logische Replikation
- FerretDB (JSON-Proxy) MongoDB-Proxy
- Zusätzliche Storage Engines
- Neue Index-Typen
- Mehrere 100 Erweiterungen –> Windows ist schwierieg
- Oracle:
orafce
- Timescale
pgvectorpgaudit- PostGIS
pg_hint_plan -> Optimizer Hintspg_repack / pg_squeeze
- Replikation und HA
- Physical streaming replication: Standby ist ro, muss gleiche Major Version haben, also KEIN Upgrade Pfad
- HA failover: Patroni hat sich durchgesetzt (Firma Compose), 2 Developer (Zalando, Microsoft)
+---------------------------------+
| HAproxy |
+----+-----------+-----------+----+
| | |
+----+----+ +----+----+ +----+----+
| Patroni | | Patroni | | Patroni | etcd
+----+----+ +----+----+ +----+----+
| | |
+---+---+ +---+---+ +---+---+
| PG DB | | PG DB | | PG DB |
+-------+ +-------+ +-------+
pg_bouncer - Connection Pooler, kann auch auch LB
- Major Upgrade –> Logische Replikation!
- PostgreSQL Worload Analyzer (Powa)
- Fehlende Enterprise Features
- Multi-Master (log. Replikation M/M geht!)
- TDE keine Lösung für Community PostgreSQL
- Flexible Account/Password-Richtlinien
- Einheitliche und integrierte Enterprise Oberfläche (OEM)
So funktioniert der Linux I/O-Stack
Vortrag von Werner Fischer (Thomas Krenn) aus Österreich
$ tunefs -l- md-raid
- I/O scheduler
- nvme-cli
- Wozu Disk? Daten nach 100 Jahren noch lesbar
- Consumer und Enterprise SSD lassen sich nicht vergleichen!
- Folien organisieren!
- VFS
- Inodes –> Metadaten
- Directory Entries
- File Objects
- VDO -> Block Ebene Dedupplizierung, macht Sinn > 2 Tbyte! –> Thomas Krenn Wiki lesen
- I/O Scheduler: mq
- SSD z. B. 16 queues
- Heute bei NVMe nicht mehr so relevant wie bei Spinning disks.
- SATA- und SAS-Geräte nur 1 Queue, NVMe 1 Queue pro vCore
- Auf 14 vCore Maschine:
$ nvme get-feature /dev/nvme0n1 -f 7 -H
get-feature:0x07 (Number of Queues), Current value:0x000d000d
Number of IO Completion Queues Allocated (NCQA): 14
Number of IO Submission Queues Allocated (NSQA): 14
- EE NVMe bis 128 Queues
$ nvme -list -v- HW Queue : SW Queue 1 : 1
Warum sollte man BTRFS verwenden?
Vortrag von Richard Albrecht
du lügt brei BtrFS!$ filefrag -v$ cp --reflink=always alt neuscrub -> auf Lesefehler prüfen.
Tausend Freiwillige, ein Ziel
Vortrag von Andreas Tille (Debian Project Leader (DPL))
Openwashing ans Licht!
Votrag von Johannes Näder, FSFE
- Freie Software 4 x V:
- Verwenden (use)
- Verstehen (understand)
- Verbessern (improve)
- Verbreiten (distribute)
- “Public money - public code”
- Source Available
- Indikatoren - genau hinsehen!
Abraham Maslow wrote in 1966: “It is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.”
Quelle: https://en.wikipedia.org/wiki/Law_of_the_instrument
Karten. Daten. Open Source. Unsere Reise zu GISA Maps
Vortrag von Clemens Schenke-Hildebrandt
Intenet Archive Scholar: Preserving the scholarly record
Vortrag von Martin Czygan, Intenet Archive (auf englisch)
Open Street Map ist (k)eine Karte
Vortrag von Falk Zscheile (Jurist?)
Databankier / Datenbankier


{kind=link}